2025-11-20_GB200 NVL72 與 Grace Blackwell 超級晶片規格比較
2025-11-20 GB200 NVL72 與 Grace Blackwell 超級晶片規格比較
☘️ Article
大衝擊!傳 NVIDIA AI 伺服器考慮改採 LPDDR,明年記憶體供應續緊縮
- 痾... 不太明白為何滿多家的標題都下得這麼聳動,NV 在 GB200 就已經在用 LPDDR 了阿 (圖)
查了 Counterpoint 原文用詞
- 查了 counterpoint 原文用詞沒這麼激烈,他想表達的其實就是 " 這波需求很多是 CSP 驅動 " 的論述,但這也不算新聞了
Counterpoint Research 原文
- 「The bigger risk on the horizon is with advanced memory as NVIDIA’s recent pivot to LPDDR means it is a customer on the scale of a major smartphone maker — a seismic shift for the supply chain which can’t easily absorb this scale of demand」, said Hwang.
- Traditionally, servers have relied on DDR memory with error correcting code (ECC) for reliability, but NVIDIA is pivoting to LPDDR for lower power consumption and handling error correction at the CPU level rather than relying on DDR5 ECC.
- Accordingly, Counterpoint forecasts a 2x increase in DRAM module prices for DDR5 64GB RDIMM across Q1 2025 to the end of 2026 in a highly constrained scenario.
調研機構 Counterpoint Research 發布最新報告
- 「調研機構 Counterpoint Research 發布最新報告指出,目前產業還面臨新問題,因為 NVIDIA 在 AI 伺服器中改採智慧手機常用的記憶體晶片,這可能使 2026 年底前讓伺服器記憶體價格翻倍。」
✍️ Abstract
- Counterpoint Research 報告:指出 NVIDIA 在 AI 伺服器 (如 GB200) 中改採 LPDDR 記憶體,此舉將對記憶體供應鏈產生重大影響,形同增加一個主要智慧型手機製造商規模的需求。
- 轉換主因:LPDDR 具備較低功耗,且錯誤校正 (ECC) 改由 CPU 層級處理。
- 價格預測:該機構預測,在供應高度受限的情況下,DDR5 64GB RDIMM 的 DRAM 模組價格從 2025 年第一季到 2026 年底可能翻倍。
- 作者觀點:認為媒體標題過於聳動,因為 GB200 早已採用 LPDDR 並非新聞。
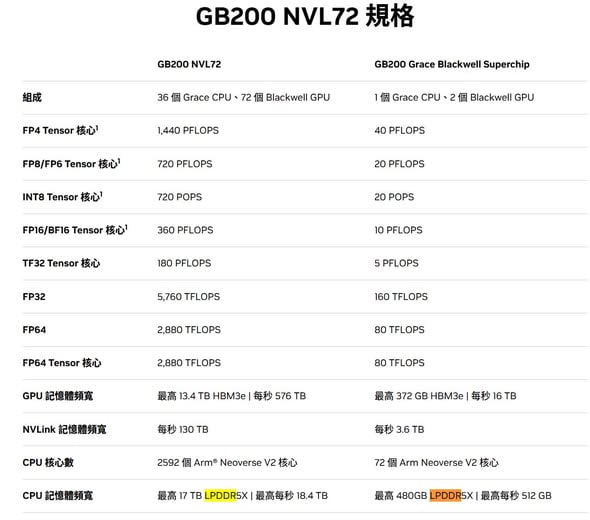
GB200 NVL72vs. GB200 Grace Blackwell Superchip
| 規格項目 | GB200 NVL72 | GB200 Grace Blackwell Superchip |
|---|---|---|
| 組成 | 36 個 Grace CPU、72 個 Blackwell GPU | 1 個 Grace CPU、2 個 Blackwell GPU |
| FP4 Tensor 核心 | 1,440 PFLOPS | 40 PFLOPS |
| FP8/FP6 Tensor 核心 | 720 PFLOPS | 20 PFLOPS |
| INT8 Tensor 核心 | 720 POPS | 20 POPS |
| FP16/BF16 Tensor 核心 | 360 PFLOPS | 10 PFLOPS |
| TF32 Tensor 核心 | 180 PFLOPS | 5 PFLOPS |
| FP32 | 5,760 TFLOPS | 160 TFLOPS |
| FP64 | 2,880 TFLOPS | 80 TFLOPS |
| FP64 Tensor 核心 | 2,880 TFLOPS | 80 TFLOPS |
| GPU 記憶體頻寬 | 最高 13.4 TB HBM3e | 每秒 576 TB | 最高 372 GB HBM3e | 每秒 16 TB |
| NVLink 記憶體頻寬 | 每秒 130 TB | 每秒 3.6 TB |
| CPU 核心數 | 2592 個 Arm Neoverse V2 核心 | 72 個 Arm Neoverse V2 核心 |
| CPU 記憶體頻寬 | 最高 17 TB LPDDR5X | 最高每秒 18.4 TB | 最高 480GB LPDDR5X | 最高每秒 512 GB |
專有名詞解釋
- PFLOPS (Peta Floating Point Operations Per Second):每秒執行千萬億次浮點運算,衡量處理器運算速度的單位。
- POPS (Peta Operations Per Second):每秒執行千萬億次運算,衡量處理器執行特定類型 (如整數) 運算速度的單位。
- TFLOPS (Tera Floating Point Operations Per Second):每秒執行萬億次浮點運算。
- Tensor 核心:圖形處理器 (GPU) 中專門設計用於執行張量 (Tensor) 運算的單元,對於深度學習和人工智慧應用至關重要。
- FP4/FP6/FP8/FP16/BF16/TF32/FP32/FP64:代表不同的浮點數精度格式,數字越小代表精度越低,但通常能提供更高的運算速度。例如,FP32 是單精度浮點數,FP64 是雙精度浮點數。INT8 則代表 8 位元整數精度。
- HBM3e (High Bandwidth Memory 3e):一種高頻寬記憶體技術,用於提供超高頻寬給 GPU 等處理器。
- LPDDR5X (Low Power Double Data Rate 5X):一種低功耗雙倍數據傳輸率同步動態隨機存取記憶體,常用於 CPU 和其他系統記憶體。
- NVLink:NVIDIA 開發的一種高速晶片間互連技術,用於 GPU 與 GPU 或 GPU 與 CPU 之間的高頻寬通訊。